In this tutorial, we'll configure everything needed to send emails from the
terminal. We'll use
msmtp, a lightweight SMTP client. For the sake of
the example, we'll use a GMail account, but any other email provider can do.
Your OS is expected to be
Debian, as usual on this blog, although it
doesn't really matter. We will also see how to store the credentials for the
email account in the system keyring. And finally, we'll go the extra mile, and
see how to configure various command-line utilities so that they automatically
use msmtp to send emails. Even better, we'll make msmtp the default email
sender, to actually avoid configuring these utilities one by one.
Prerequisites
Strong prerequisites (if you don't recognize yourself here, you probably landed
on the wrong page):
- You run Linux on your computer (let's assume a Debian-like distro).
- You want to send emails from your terminal.
Weak prerequisites (if your setup doesn't match those points exactly, that's
fine, you can still read on):
- Your email account is a GMail one.
- Your desktop environment is GNOME.
GMail account setup
For a GMail account, there's a bit of configuration to do. For other email
providers, I have no idea, maybe you can just skip this part, or maybe you will
have to go through a similar procedure.
If you want an external program (
msmtp in this case) to talk to the GMail
servers on your behalf, and send emails, you can't just use your usual GMail
password. Instead, GMail requires you to generate so-called
app passwords,
one for each application that needs to access your GMail account.
This approach has several advantages:
- it will basically work, GMail won't block you because it thinks that you're
trying to sign in from an unknown device, a weird location or whatever.
- your main GMail password remains secret, you won't have to write it down
in any configuration file or anywhere else.
- you can change your main GMail password, no breakage, apps will still work as
each of them use their own passwords.
- you can revoke an app password anytime, without impacting anything else.
So app passwords are a good idea, it just requires a bit of work to set it up.
Let's see what it takes.
First,
2-Step Verification must be enabled on your GMail account. Visit
https://myaccount.google.com/security, and if that's not the case, enable it.
You'll need to authorize all of your devices (computer(s), phone(s) and so on),
and it can be a bit tedious, granted. But you only have to do it once in a
lifetime, and after it's done, you're left with a more secure account, so it's
not that bad, right?
Enabling the 2-Step Verification will unlock the feature we need:
App
passwords. Visit
https://myaccount.google.com/apppasswords, and under
"
Signing in to Google", click "
App passwords", and generate one. An app
password is a 16 characters string, something like
qwertyuiopqwerty. It's
supposed to be used from only one place, ie. from ONE application that is
installed on ONE device. That's why it's common to give it a name of the form
application@device, so in our case it could be
msmtp@laptop, but really
it's free form, choose whatever name suits you, as long as it makes sense to
you.
So let's give a name to this app password, write it down for now, and we're
done with the GMail config.
Send your first email
Time to get started with
msmtp.
First thing first, installation, trivial:
Let's try to send an email. At this point, we did not create any configuration
file for msmtp yet, so we have to provide every details on the command line.
# Write a dummy email
cat << EOF > message.txt
From: YOUR_LOGIN@gmail.com
To: SOMEONE_ELSE@SOMEWHERE_ELSE.com
Subject: Cafe Sua Da
Iced-coffee with condensed milk
EOF
# Send it
cat message.txt msmtp \
--auth=on --tls=on \
--host smtp.gmail.com \
--port 587 \
--user YOUR_LOGIN \
--read-envelope-from \
--read-recipients
# msmtp prompts you for your password:
# this is where goes the app password!
Obviously, in this example you should replace the uppercase words with the
real thing, that is, your email login, and real email addresses.
Also, let me insist, you must enter the
app password that was generated
previously, not your real GMail password.
And it should work already, this email should have been sent and received by
now.
So let me explain quickly what happened here.
In the file
message.txt, we provided
From: (the email address of the person
sending the email) and
To: (the destination email address). Then we asked
msmtp to re-use those values to set the
envelope of the email with
--read-envelope-from and
--read-recipients.
What about the other parameters?
--auth=on because we want to authenticate with the server.--tls=on because we want to make sure that the communication with the
server is encrypted.--host and --port tells where to find the server. If you don't use GMail,
adjust that accordingly.--user is obviously your GMail username.
For more details, you should refer to the
msmtp documentation.
Write a configuration file
So we could send an email, that's cool already.
However the command to do that was a bit long, and we don't want to juggle with
all these arguments every time we send an email. So let's write down all of
that into a configuration file.
msmtp supports two locations:
~/.msmtprc and
~/.config/msmtp/config, at
your preference. In this tutorial we'll use
~/.msmtprc for brevity:
cat << 'EOF' > ~/.msmtprc
defaults
tls on
account gmail
auth on
host smtp.gmail.com
port 587
user YOUR_LOGIN
from YOUR_LOGIN@gmail.com
account default : gmail
EOF
And for a quick explanation:
- under
defaults are the default values for all the following accounts.
- under
account are the settings specific to this account, until another
account line is found.
- finally, the last line defines which account is the default.
All in all it's pretty simple, and it's becoming easier to send an email:
# Write a dummy email. Note that the
# header 'From:' is no longer needed,
# it's already in '~/.msmtprc'.
cat << 'EOF' > message.txt
To: SOMEONE_ELSE@SOMEWHERE_ELSE.com
Subject: Flat White
The milky way for coffee
EOF
# Send it
cat message.txt msmtp \
--account default \
--read-recipients
Actually,
--account default is not needed, as it's the default anyway if you
don't provide a
--account argument. Furthermore
--read-recipients can be
shortened as
-t. So we can make it real short now:
At this point, life is good! Except for one thing maybe: we still have to type
the password every time we send an email. Surely it must be possible to avoid
that annoyance...
Store your password in the system keyring
For this part, we'll make use of the
libsecret tool to store the password
in the system keyring via the
Secret Service API. It means that your
desktop environment should implement the Secret Service specification, which is
the case for both GNOME and KDE.
Note that GNOME provides
Seahorse to have a look at your secrets, KDE has
the
KDE Wallet. There's also
KeePassXC, which I have only heard of but
never used. I guess it can be your password manager of choice if you use
neither GNOME nor KDE.
For those running an up-to-date Debian unstable, you should have
msmtp >=
1.8.11-2, and you're all good to go. For those having an older version than
that however, you will have to install the package
msmtp-gnome in order to
have msmtp built with libsecret support. Note that this package depends on
seahorse, hence it pulls in a good part of the GNOME stack when you install
it. For those not running GNOME, that's unfortunate. All of this was discussed
and fixed in
#962689.
Alright! So let's just make sure that the libsecret tools are installed:
sudo apt install libsecret-tools
And now we can store our password in the system keyring with this command:
secret-tool store --label msmtp \
host smtp.gmail.com \
service smtp \
user YOUR_LOGIN
If this looks a bit too magic, and you want something more visual, you can
actually fire a GUI like
seahorse (for GNOME users), or
kwalletmanager5
(for KDE users), and then you will see what passwords are stored in there.
Here's a screenshot of Seahorse, with a msmtp password stored:
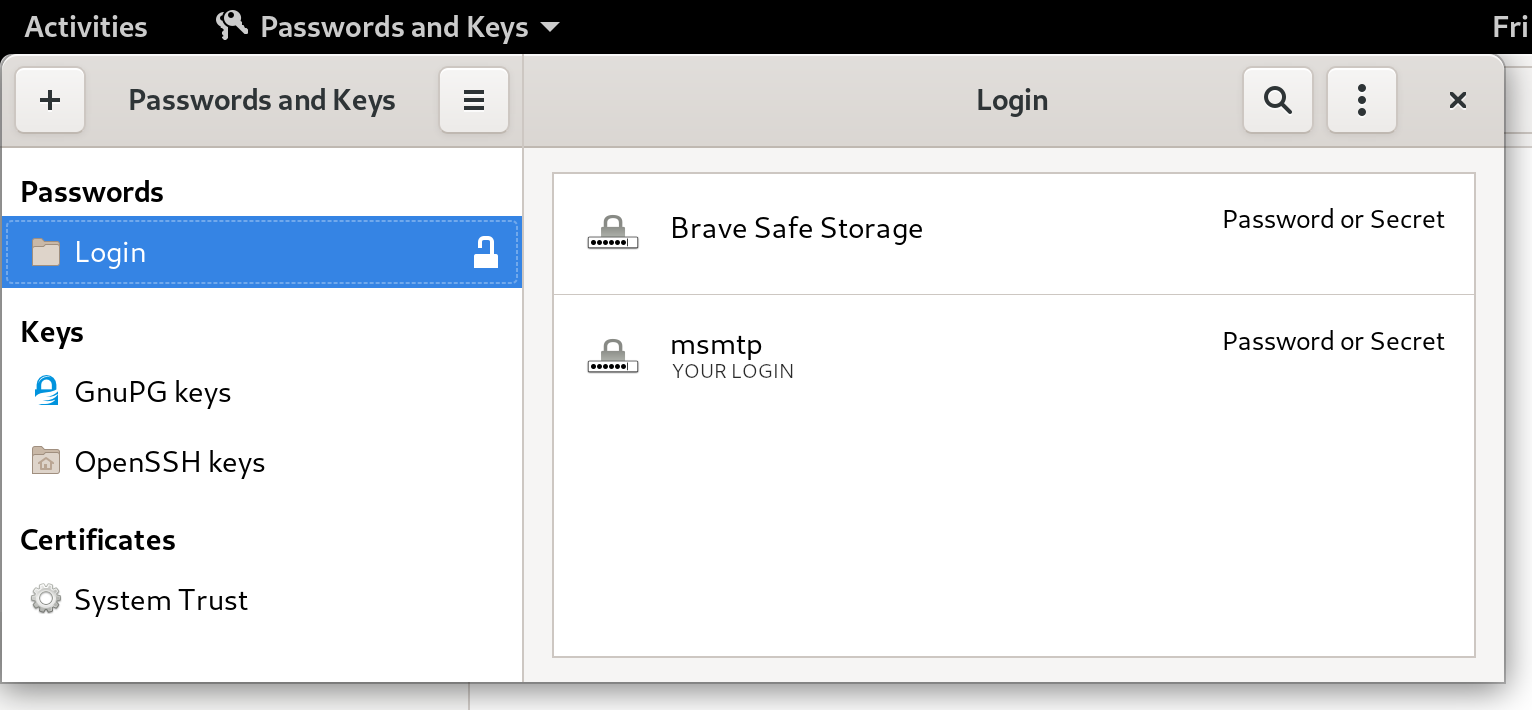
Let's try to send an email again:
No need for a password anymore, msmtp got it from the system keyring!
For more details on how msmtp handle the passwords, and to see what other
methods are supported, refer to the
extensive documentation.
Use-cases and integration
Let's go over a few use-cases, situations where you might end up sending emails
from the command-line, and what configuration is required to make it work with
msmtp.
Git Send-Email
Sending emails with git is a common workflow for some projects, like the Linux
kernel. How does
git send-email actually send emails? From the
git-send-email manual page:
the built-in default is to search for sendmail in /usr/sbin, /usr/lib and
$PATH if such program is available
It is possible to override this default though:
--smtp-server=
[...] Alternatively it can specify a full pathname of a sendmail-like program
instead; the program must support the -i option.
So in order to use msmtp here, you'd add a snippet like that to your
~/.gitconfig file:
[sendemail]
smtpserver = /usr/bin/msmtp
For a full guide, you can also refer to
https://git-send-email.io.
Debian developer tools
Tools like
bts or
reportbug are also good examples of command-line tools
that need to send emails.
From the
bts manual page:
--sendmail=SENDMAILCMD
Specify the sendmail command [...] Default is /usr/sbin/sendmail.
So if you want bts to send emails with msmtp instead of sendmail, you must use
bts --sendmail='/usr/bin/msmtp -t'.
Note that bts also loads settings from the file
/etc/devscripts.conf and
~/.devscripts, so you could also set
BTS_SENDMAIL_COMMAND='/usr/bin/msmtp
-t' in one of those files.
From the
reportbug manual page:
--mta=MTA
Specify an alternate MTA, instead of /usr/sbin/sendmail (the default).
In order to use msmtp here, you'd write
reportbug --mta=/usr/bin/msmtp.
Note that reportbug reads it settings from
/etc/reportbug.conf and
~/.reportbugrc, so you could as well set
mta /usr/bin/msmtp in one of those
files.
So who is this sendmail again?
By now, you probably noticed that
sendmail seems to be considered the
default tool for the job, the "traditional" command that has been around for
ages.
Rather than configuring every tool to use something else than sendmail,
wouldn't it be simpler to actually replace sendmail by msmtp? Like, create a
symlink that points to msmtp, something like
ln -sr /usr/bin/msmtp
/usr/sbin/sendmail? So that msmtp acts as a drop-in replacement for sendmail,
and there's nothing else to configure?
Answer is yes, kind of. Actually, the
first msmtp feature
that is listed on the homepage is "
Sendmail compatible interface (command
line options and exit codes)". Meaning that msmtp
is a drop-in replacement
for sendmail, that seems to be the intent.
However, you should refrain from creating or modifying anything in
/usr, as
it's the territory of the package manager,
apt. Any change in
/usr might be
overwritten by apt the next time you run an upgrade or install new packages.
In the case of msmtp, there is actually a package named
msmtp-mta that will
create this symlink for you. So if you really want a definitive replacement for
sendmail, there you go:
sudo apt install msmtp-mta
From this point, sendmail is now a symlink
/usr/sbin/sendmail
/usr/bin/msmtp, and there's no need to configure
git,
bts,
reportbug or
any other tool that would rely on sendmail. Everything should work "out of the
box".
Conclusion
I hope that you enjoyed reading this article! If you have any comment, feel
free to send me a short email, preferably from your terminal!
 A new release of the dang package is now on CRAN, roughly one year after the last release. The dang package regroups a few functions of mine that had no other home as for example
A new release of the dang package is now on CRAN, roughly one year after the last release. The dang package regroups a few functions of mine that had no other home as for example  The main point is: run the initial script and the later updates in the same configuration, which means the target branch needs to be reset to the upstream branch each time, before it's rewritten again by
The main point is: run the initial script and the later updates in the same configuration, which means the target branch needs to be reset to the upstream branch each time, before it's rewritten again by  This line is called a command prompt and it tells you four pieces of information:
This line is called a command prompt and it tells you four pieces of information:
 This is a shorthand notation that the shell uses to make this output shorter
when possible.
This is a shorthand notation that the shell uses to make this output shorter
when possible.  actually tells you that you are currently in the
actually tells you that you are currently in the  This is part of a series of posts on compiling a custom version of Qt5 in order
to develop for both amd64 and a Raspberry Pi.
This is part of a series of posts on compiling a custom version of Qt5 in order
to develop for both amd64 and a Raspberry Pi.

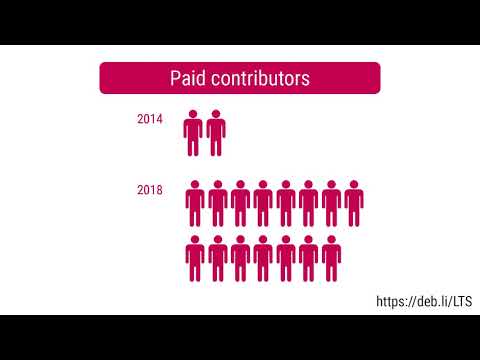
 Here is my monthly update covering what I have been doing in the free software world during May 2020 (
Here is my monthly update covering what I have been doing in the free software world during May 2020 (









 I just had a weekend full of very successful serious geekery. On a whim I thought: Wouldn't it be nice if people could interact with my game
I just had a weekend full of very successful serious geekery. On a whim I thought: Wouldn't it be nice if people could interact with my game 
 Earlier this month I had the pleasure of attending the Web Engines Hackfest, hosted by Igalia at their offices in A Coru a, and also sponsored by my employer,
Earlier this month I had the pleasure of attending the Web Engines Hackfest, hosted by Igalia at their offices in A Coru a, and also sponsored by my employer, 



 The
The {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}